-개요 / 차별점-
기존에는
Text Detection -> Text Recognition 의 2 stage 모델이 많이 발전했다면,
이 논문에서 말하는 Text Spotting 은 두 stage 를 한번에 하는 것이다.
이렇게 Text Spotting 을 하게 되면,
1. cost 를 줄일 수 있고,
2. 두 개의 스테이지에서 피쳐를 공유하여 더 좋은 성능을 얻을 수 있다.
기존의 End-To-End 모델들과 다른 부분
- Shared Convolution
- Oriented Text 에 대한 정확도 개선.
-Relation Works-
-----------------------------------------------------------------------------------------------------------------------------------
<<<DETECTION>>>
- Rotation based framework
Arbitary-Oriented Scene Text Detection via Rotation Propsals
< Detection 단계에서 roi rotation을 도입.>
순서 = horizontal proposals -> rotation proposals -> refinement
<<<ROI ROTATE>>>
기존 : ROI POOLING , ROI ALIGN
등이 존재한다.
해당 모델 : ROI ROTATE 이용.
<<<RECOGNITION>>>
기존 : Chacter Level
최근 : 1. Word Classification , 2. Sequence to Label Decode , 3. Sequence to Sequence Decode
해당 모델 : Deep Recurrent Models & Connectionist Temporal Classificeation (CTC)
그대로 가져옴.
-----------------------------------------------------------------------------------------------------------------------------------
-모델 구조-
-----------------------------------------------------------------------------------------------------------------------------------
<<<전체 구조>>>
Shared Convolution -> Text Detection Branch -> Predicted BBoxes
등이 존재한다.
해당 모델 : ROI ROTATE 이용. -> ROI Rotate -> Text Recognition Branch -> Predicted Texts
<<<BackBone>>>
BackBone = ResNet-50
- Feature Map 을 1/32 사이즈가 아닌 1/4 사이즈로 구성함. (upsampling) // 얇게 쓰여진 글씨를 고려함.
<<<DETECTION>>>
BackBone (Shared Feature Map) 을 거치고 온 1/4 사이즈의 Feauture Map 에
(Dense per-pixel predictions of words) Convolution Filter 를 한 개 적용시킨다.
픽셀 당 6개의 채널이 생기며(뇌피셜)
첫번째 채널에는 텍스트의 유무에 따른 확률값 / 4개의 채널에는 상단,하단,왼쪽단,오른쪽단 까지의 거리 / 마지막 채널에는 BB의 각도를 나타낸다.
박스 후보군은 1. Thresholing , 2. NMS 를 거치고 나온다.
이 후 OHEM 을 적용한다. (2%의 F-Measure 향상 / ICDAR 2015) : Class Imbalance (positive / negative samples) 문제 해결.
OHEM :
data 에서 positive 와 hard negative example 로 data를 필터링하고 학습.
Hard-negative sample 은 각 anchor box 중 score 가 높게 나왔으나 GT 가 음성인 (배경사진) 후보군을 의미한다.
FOCAL LOSS :
GT 가 1인 경우 =
P(확률)이 높게 나온 경우 -> 더 쉬운 샘플, 더 적은 가중치를 줌.
P(확률)이 낮게 나온 경우 -> 더 어려운 샘플, 더 큰 가중치를 줌.
GT 가 0인 경우 =
P(확률)이 높게 나온 경우 -> 더 어려운 샘플, 더 큰 가중치를 줌.
P(확률)이 낮게 나온 경우 -> 더 쉬운 샘플, 더 작은 가중치를 줌.
OHEM 보다 일반적으로 성능이 더 좋다고 한다. Retina-Net 에서 제안됨.
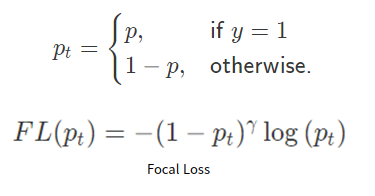
---- One-stage Detector 에서는 영상 전체에서 후보가 매우 많이 나온다. (Class Imbalance 가 심함) -----
따라서 OHEM , Focal Loss 등으로 해결해주어야 함.
Detection 전체에 대한 Loss Function = Classfication Loss + Regression Loss

-Classification Loss-

-Regression Loss-
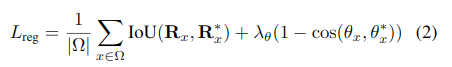
<<<ROI ROTATE>>>
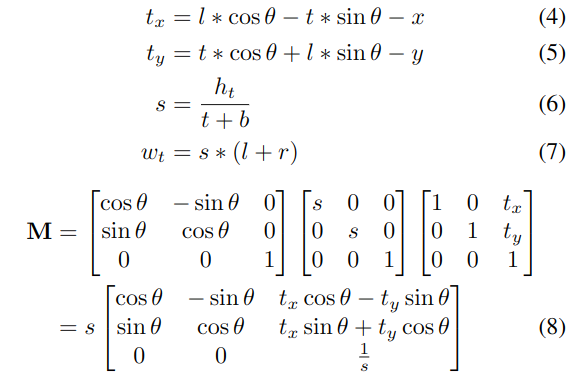

- 높이를 8로 고정시키고, 가로를 가변적으로 만들며, 오른쪽에 패딩을 두는 구조로 Rotate함.
ROI ROTATE 는 기존의 방식인 ROI POOLING 과 ROI ALIGN 에 비해 몇가지 이점을 가진다.
ROI POOLING 은 RRPN 모델에서 제시되었는데, 최대풀링을 통해 회전 영역을 고정 크기 영역으로 변환한다.
반면에, ROI ROTATE는 출력 값을 계산하기 위해 이중 선형 보간법을 사용한다.
-Bilinear Interpolation (이중 선형 보간법) 이용. -> 출력 형상의 길이를 가변적으로 만든다. (텍스트에 적합함.)
= 선형보간법을 x축과 y축으로 두 번 적용하여 값을 유추하는 방법.
Oriented Text Region Box -> Canonical Box
*Proposal 된 원본의 Bounding Box 부분을 ROI ROTATE -> Recognition 하는 것이 아니라, Feature Map을 ROI ROTATE 함.*

<<<RECOGNITION>>>
(VGG , Pooling with reduction along height axis only) -> BiLSTM -> FL -> CTC decoder



-----------------------------------------------------------------------------------------------------------------------------------
논문내에서 더 읽어보고 추가해야 할 내용
1. Recognition 보강.
2. 다른 모델들과의 비교.
3. 2-stage Model 과의 비교 // 2-stage 에서의 실패 case 들과 Unified Network 를 가진 FOTS 가 이 case 들을 극복한 이유.
4. S,W,G // End-to-End 와 Word Spotting 정확한 차이
참고한 동영상 : www.youtube.com/watch?v=hOFViMbYnrs&ab_channel=SoyeonKim